How to Forecast Generative AI API Costs Before You Launch an AI Feature
Turn AI API pricing into a real product decision: estimate one request, scale it through user behavior and plan caps, and test whether the feature fits your pricing before you ship.
Stress-test one AI feature inside your plan
Estimate one request, scale it through real user behavior, and see how much of your plan economics the feature consumes over time.
One paying user: cumulative subscription revenue vs cumulative AI spend (24 months).
Why founders get AI API cost wrong
Founders rarely ignore AI API cost. The gap is usually timing.
A team adds an AI feature, checks the provider pricing page, sees that one prompt or one generated asset looks cheap enough, and moves on. Modeling often waits until the first meaningful bill. That works for a prototype. It is a weak way to plan something that will sit inside a paid product.
AI cost rarely breaks on a single request. It breaks when a request becomes a feature, the feature sits in a plan, and real customers use it with real behavior. Economics then depend on more than the provider's rate card: how the feature works, how often people use it, how much each segment gets, and whether subscription price can carry the promise.
A useful founder question pairs cost with fit: can this feature work inside my product before I ship it?
Start from the feature, not the vendor bill
Early models often include a line like "OpenAI cost" or "AI vendor cost." It looks tidy, but it hides the logic you need for decisions.
Stronger modeling starts from the feature. What exactly is the user doing — chatting, generating an image, creating a video clip, rewriting text, summarizing a document? Until that is clear, the cost line stays too abstract to guide product choices.
You are designing an experience and deciding how much of it belongs in each plan. The feature is the commercial unit. Model it that way and the financial questions sharpen: which plans include it, how generous the allowance is, whether trial users get access, whether current price can support it.
Those are pricing and margin questions as much as infrastructure questions.
What you need to estimate before you model AI API cost
Invoice-level precision is optional for a solid early call. What you need first is a realistic pass on five things.
- 1
The feature itself
What exactly is the user doing: chatting with an assistant, generating an image, creating a video clip, summarizing a document, or something else?
- 2
One average request
What does one normal use of the feature look like? For chat, that usually means one prompt plus one response. For image or video, it may mean one generated asset or one generated clip.
- 3
Monthly usage rhythm
How often will a real user use this feature in a month? Think in sessions and actions, not just “heavy” or “light” usage.
- 4
Access and caps
Who gets the feature, and how much of it? Free users, trial users, Basic, Pro, team plans — each can have a different allowance.
- 5
Pricing and margin fit
Once the feature is inside a plan, does the subscription price still support the cost? This is the real founder question.
Define one request
Many write-ups swing between too technical and too vague. The useful middle is smaller.
For modeling, skip reproducing every invoice line. Aim for one realistic average use of the feature.
Take AI chat. One average request is often one user message plus one model response. For cost, that maps to input and output: input is what you send for that interaction — the prompt plus typical context or instructions. Output is what the model returns.
Perfect token science can wait. You need a believable picture of a normal request in your product. Short prompts and tight answers look nothing like a research assistant with long context and long responses. Outside chat, one request might be one image or one clip of a certain length.
Real provider pricing has branches: caching, SKUs, volume, and more than a single headline rate — the sort of detail spelled out on OpenAI’s API pricing and Anthropic’s pricing, when you want to check the source. For a first pass on whether the feature fits the business, a conservative simplified request cost that you refine later usually beats waiting for perfect precision.
Scale through usage
With one concrete request, the focus shifts from a headline monthly bill to how people actually consume the feature.
Many models jump from cost per request to a rough total without usage rhythm. Richer thinking follows the product: opens per month, requests per session, differences between free and paid, which plans deserve higher limits because the feature carries the value story, and where guardrails should tighten.
Here AI cost meets product design. The same per-request cost can be harmless or painful depending on how much usage you bake in. A cheap request with a loose cap can still hurt. A pricier request can work in the right tier with the right allowance.
Scale cost through segments, monthly caps, and realistic utilization — not one blended "average" customer.
AI chat example
Picture an assistant inside a subscription product: strong enough to help conversion and retention, not so central that every tier needs unlimited access.
The founder wants a small allowance on free, more on Basic, more still on Pro — and needs to know whether today's prices can carry that ladder. The aim is to ship AI in a way that still works economically, not to tick an "AI" box on the pricing page.
The model pays off when you compare product design to economics: Is the free allowance tight enough? Is Basic too generous for its price? Does Pro justify its price with room left? Is real usage likely to be light, medium, or heavy?
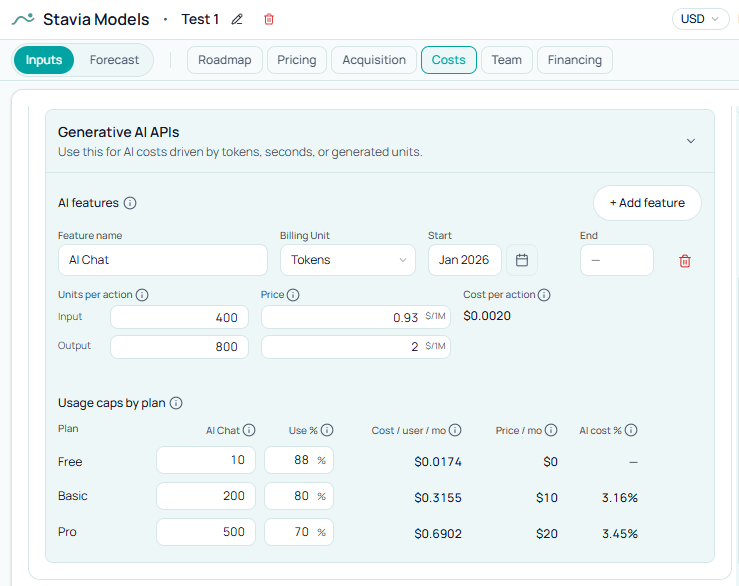
Caps and free use
Model choice gets attention; caps often do not, and caps are where the promise hardens.
In a subscription product, the cap is where provider rates turn into a commercial promise. Free gets some access, Basic more, Pro more still — at that point you are pricing product, not wiring diagrams.
Free and trial usage need a visible line in the model. One request can look cheap in isolation and expensive once meaningful pre-paid usage scales. Teams often surface AI early for onboarding and conversion; that can be right. It still belongs in the forecast explicitly, not inside a single blended user.
Paid tiers surface the same tension: the feature may fit Pro but strain Basic, or free may need to stay deliberately small. Those are the calls a model should surface before launch.
For how access mode shapes when that usage hits the funnel, see Free Trial vs Freemium.
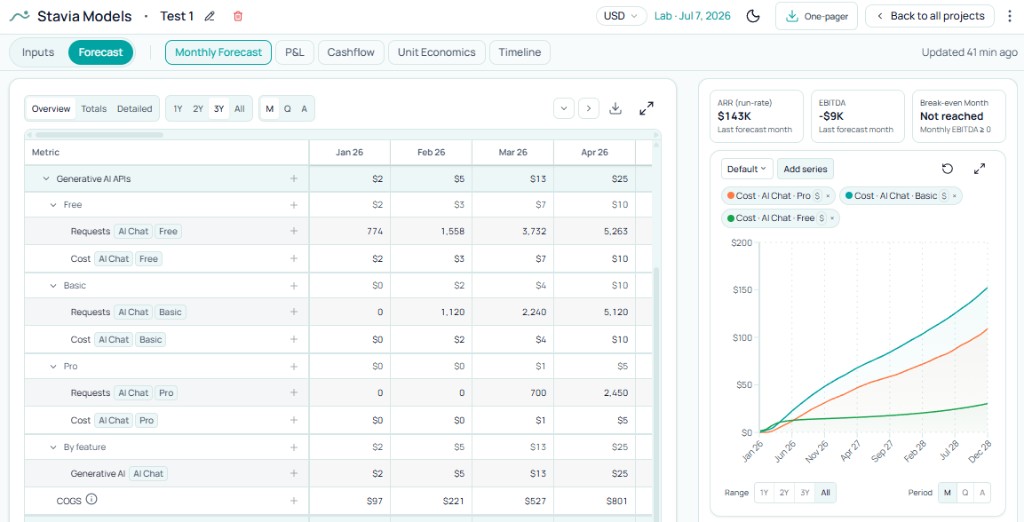
Margin and burn
Conversations about AI features often stop at the vendor bill. The operating question runs longer.
Modeled AI cost sits in COGS, so it moves gross margin. Margin shifts contribution, cash retained from revenue, and room to fund growth — tighter or looser depending on the feature.
Treat AI API cost as part of the operating model, not a footnote. You want to see whether the feature leaves enough room for healthy growth, not only that it "costs something."
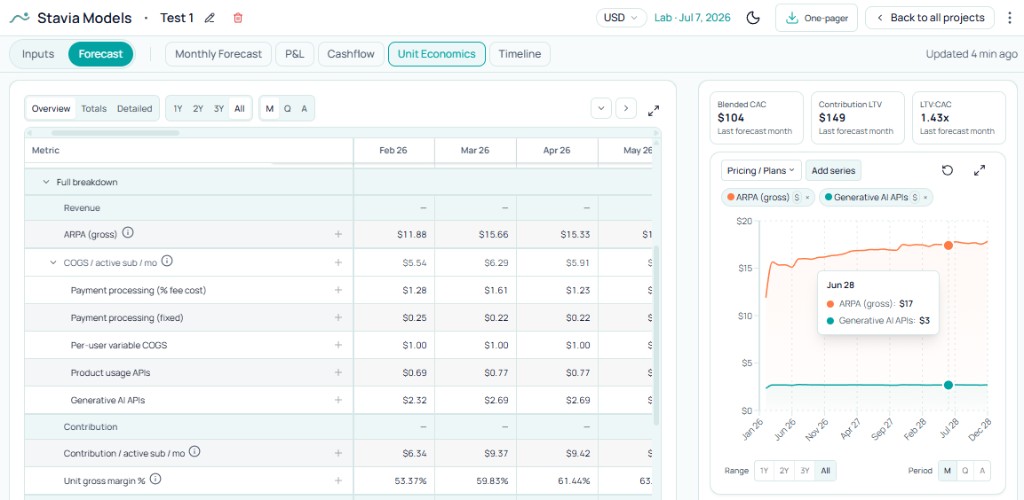
Where unit economics make the decision clearer
COGS confirms the cost exists. Unit economics ask whether it still belongs in the plan.
With AI API cost next to ARPA, contribution, and other per-subscriber lines, thinking shifts from abstract spend to product economics: Is the feature a manageable slice of the subscription? Does it leave enough value after price? Is it quietly eating what the plan is supposed to deliver?
Trade-offs get concrete: viable in Pro, uncomfortable in Basic; chat fits the ladder while video does not; worth keeping only with tighter caps or lower expected use on lower tiers.
Video and other features
The same structure holds when the modality changes.
Video, images, or other usage-based AI may define one request as an asset, a render, a clip, or seconds rather than prompt plus reply. The sequence stays the same: cost one normal action, then who gets access, monthly cap, and likely use against that cap.
Pricier modalities can strain entry tiers fast. A strong differentiator can still be the wrong package for a low price if the allowance is too loose. That usually points to packaging work, not a bad feature.
Common mistakes
In Stavia
Build one AI feature at a time.
Define one average action — typical prompt and response for chat, typical generated unit for image or video — then decide packaging: what free users get, what each paid plan gets, and realistic utilization by segment.
Do not stop at the input screen. Read the feature through COGS, then unit economics. Configuration matters because it answers whether your current pricing and plan structure can support what you are shipping.
Stavia is one place to implement that workflow: the same logic you would want in a serious early-stage model, tied to the rest of the forecast instead of a side sheet.
It sits alongside pricing and plan design: revenue assumptions and variable costs only work when they can speak to each other in one model.
Conclusion
AI API cost turns risky when it stays a technology detail instead of a product and margin decision.
Sequence matters: the feature, then the request, then real consumption, then the cap and plan, then the margin that has to carry it.
Modeling helps before launch because it surfaces the right questions early enough to change the product, packaging, or price — not because it predicts usage perfectly. Generative AI COGS sits inside a SaaS and AI startup financial model where pricing, usage caps, and runway share one forecast.
About the author

Anastasiia Nikolaeva
Founder of Stavia Models
Anastasiia Nikolaeva is a financial modeling consultant and the founder of Stavia Models. She has built financial models for SaaS, AI, marketplace, and other startup business models, helping founders plan pricing, growth, fundraising, and unit economics. Stavia Models is based on this hands-on consulting experience and turns that modeling logic into a guided product.